待办列表的份数和多面学习:4)专业特性团队

待办列表的份数和多面学习:3)特性组
2020年2月6日
为什么敏捷团队应该做两级估算
2020年2月6日
待办列表的份数和多面学习系列的四篇文章包括:
本篇为系列之四:专业特性团队
在这篇文章中,我们将来看专业特性团队的结构,探索它们待办列表的相关动态,以分析其对敏捷性的影响并找到优化敏捷性的杠杆。
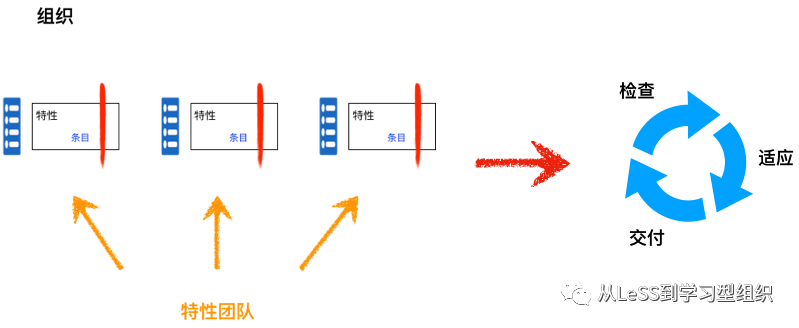
特性团队负责端到端地交付客户价值,因此要交付价值只有一份待办列表与之相关,也就是整个团队共享工作和一个优先级。然而整个组织有多个特性团队,而且每个团队有自己的待办列表。他们负责不同的客户领域,因此被称为专业特性团队。在不同待办列表里的工作是相互独立的。
为效率增加待办列表
让我们还是来问一下为什么多个特性团队会有多份待办列表,答案仍是在基于效率的思考方式。
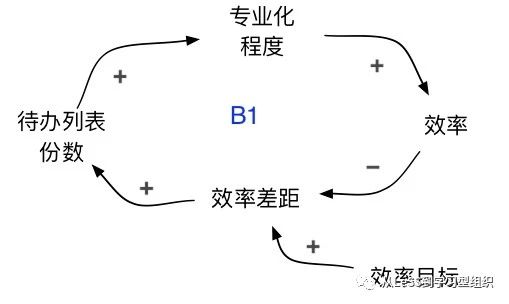
B1回路:专业化以获取效率
这跟在职能团队和组件团队结构中看到的是同样的回路。存在一个显式或者隐式的效率目标,由此产生效率差距,导致待办列表的增加。待办列表越多,专业化程度越高,效率越高,从而缩小效率差距。
然而,这里的专业化是不同类型的专业化。不同于职能团队在职能上专业化和组件团队在组件上专业化,特性团队是在客户领域上专业化。这也产生了不同的影响。
对适应能力的“意外”影响因为特性团队能够独立交付客户价值,有多份待办列表并不会对端到端周期时间产生直接影响。意外的影响是对适应能力。
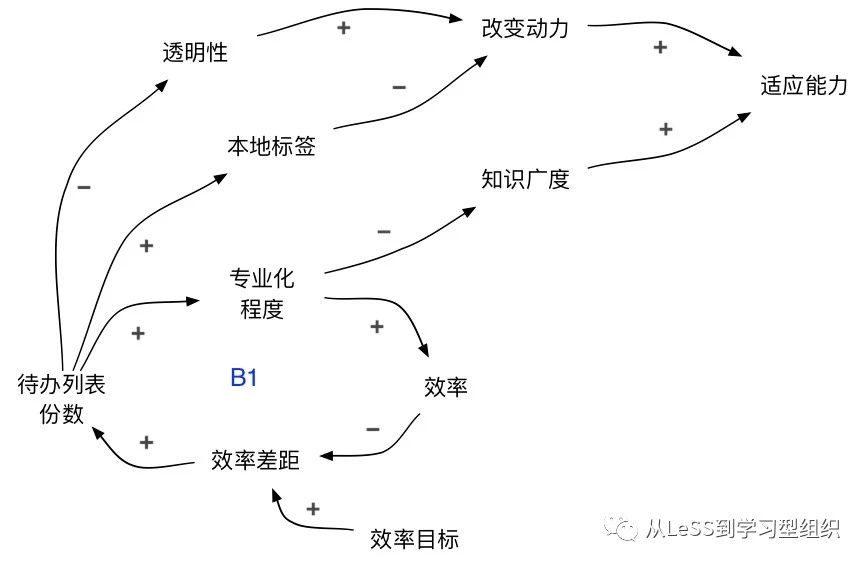
在图中的上半部分,存在三条从“待办列表份数”到“适应能力”的链路:
- 待办列表越多,专业化程度越高,知识广度越窄,适应能力越低
- 待办列表越多,本地标签越强,响应变化的动力越低,适应能力越低
- 待办列表越多,透明性越低,响应变化的动力越低,适应能力越低
所有这些链路都表明更多的待办列表会导致更低的适应能力。
为了有更高的适应能力,我们需要:
- 增加透明性,以使我们看到适应的需要
- 减少本地标签带来的竖井,以使我们有意愿去适应
- 增加知识广度,以使我们有技能去适应
多面学习以减少待办列表让我们接着在特性团队的上下文中来看如何驱动待办列表的减少。
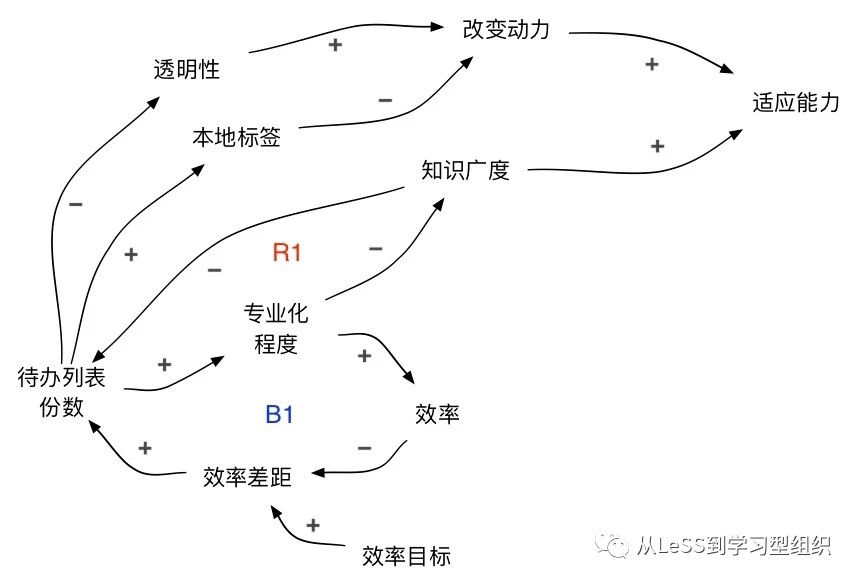
R1回路:减少待办列表驱动广度学习
待办列表越多,专业化程度越高,知识广度越窄。然后狭窄的知识广度又成了需要更多待办列表的原因,这样就形成增强的R1回路。这个回路很容易工作在往更多待办列表的方向,我们如何能将它反转?
还是一样的增强回路,但是让它这样工作 – 待办列表越少,专业化程度越低,知识广度越宽,然后就可以有更少的待办列表。。。这里的挑战是降低专业化程度并不会自动带来更宽的知识广度。我们需要多面学习以增加知识广度。
更少的待办列表会驱动多面学习;而多面学习又让我们可以有更少的待办列表。它们之间互为促进。因此,待办列表的份数本身就是一个重要的杠杆 – 让多个特性团队拥有一份待办列表。
上述分析是和对职能团队和组件团队的分析完全一致的。有什么区别?这里的知识广度是关于客户领域,而非职能或组件。这里的待办列表是产品待办列表,而非职能或组件待办列表。这里的多面学习是跨领域学习,而非跨职能或跨组件学习。
跨领域学习的技术有哪些?LeSS提供了一个指南,是关于多团队待办列表梳理的。这是让任何特性团队都尽可能广泛地学习同一待办列表里条目的关键实践。事实上,当你开始导入LeSS时,推荐缺省做全团队待办列表梳理,以最大化学习。在多团队待办列表梳理中,不是让不同特性团队梳理不同条目,而是创建由不同特性团队成员组成的混合组,让他们来梳理不同条目。他们通过发散合并的方式来在共享一份产品待办列表的那些特性团队之间获得最大的跨领域学习。
总结起来,特性团队相关的待办列表也是为了效率,但它们是对适应能力,而非端到端周期时间,造成了意外的影响。跨领域学习能减少产品待办列表,而更少的产品待办列表又能驱动跨领域学习。
结论让我们把各种类型的待办列表、专业化和多面学习放在一起来最后总结这个系列。

引入各种待办列表背后的驱动力是通过专业化以获取更高的效率。它们专业化的内容不同,分别是围绕职能、组件和客户领域。它们带来不同的问题。职能待办列表和组件待办列表使得为了交付客户价值团队之间形成了依赖,因此它们最主要的影响是对端到端周期时间。而产品待办列表相互独立,它最主要的影响是对适应能力。
关键杠杆都在于多面学习,但却是不同类型的多面学习。跨职能学习能减少职能待办列表;跨组件学习能减少组件待办列表;跨领域学习则能减少产品待办列表。
这样我们就结束了这个系列 – 待办列表份数和多面学习。



{kind=link}
{kind=link}
{kind=link}