
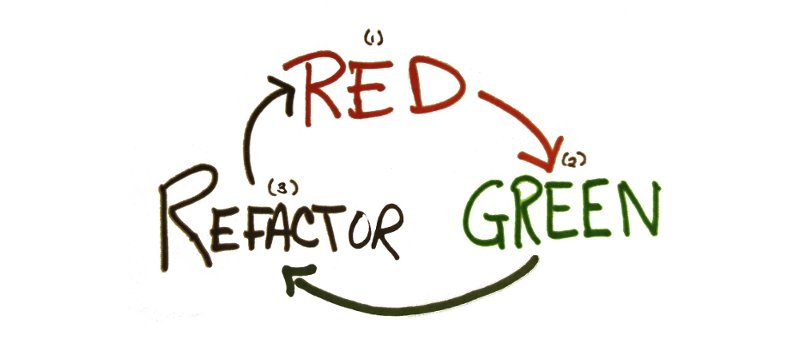
写给想要上手试试 TDD,却不知从何入手的同学。
(上)集在这里:http://www.uperform.cn/tdd-test-driven-development-practice-1
第三个大任务
欢迎回来。在开始第三个大任务“处理 2 个参数”之前,要注意,我们还没有对这个任务做拆解。是的,记住,
一定要拆小了再做。
这个任务怎么拆呢?这里,参数个数已经确定了(必须是两个),那么还有哪些没确定的东西?那就是参数类型。两个参数,三种类型,一共有六种排列方式。不好选。不过我们可以先分个类:从两个参数的类型的异同方面看。你希望首先处理两个不同类型的参数,还是两个相同类型的参数?这个不用纠结吧,肯定是两个相同类型啊,因为这样处理
难度更低。
然后,你会选择两个什么参数类型?两个布尔?两个整数?还是两个字符串?思考一下。直观上感觉,两个布尔可能是最简单的。但是我们的情况不是这样,为什么?这就要从我们目前的实现代码说起了。我们目前的代码,是连续从 commandLine 里面“吃”两个部分,并将第一部分作为标志,第二部分作为参数值。而布尔型参数是不需要传值的,所以现有代码逻辑会导致第二个参数的标志,被当做第一个参数的值,被“吃”掉。所以首先处理两个需要传值的参数类型是更简单的。就暂定两个整数型吧,更新任务清单:
- 处理 2 个参数
- 处理 2 个整数型的参数
接下来呢?有必要再拆出“处理 2 个字符串型的参数”吗?没有必要,因为参数类型转换的逻辑是已经有了的。拆出这个来,不会驱动我们的实现代码。所以,接下来应该处理布尔型参数:
- 处理 2 个参数
- 处理 2 个整数型的参数
- 处理 2 个布尔型的参数
相同类型的都拆完了,接下来是不同类型的参数。该怎么拆呢?暂时没有什么头绪。没关系,我们可以把这两个小任务做完了再看,还是延迟决定。
又可以开始愉快的编码了。首先做什么不用再说了吧,先写一个失败的测试:
describe('处理 2 个参数', () => {
it('处理 2 个整数型的参数', () => {
let schemas = [IntegerSchema('p'), IntegerSchema('q')];
let parser = new ArgumentParser(schemas);
let result = parser.parse('-p 8080 -q 9527');
expect(result.get('p')).toEqual(8080);
expect(result.get('q')).toEqual(9527);
});
});
保存,不出意外的变红了。为啥?当然是还没有实现嘛。目前的代码只能从 commandLine 里面取出第一个参数的标志和值,没有处理后续参数。所以,我们只需要把 if 改成 while 就可以了:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let tokens = commandLine.split(' ').filter(t => t.length);
while (tokens.length) {
let flag = tokens.shift().substring(1);
let value = tokens.shift();
let schema = this.schemas.find(s => s.flag === flag);
let arg = args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
return new Arguments(args);
}
保存,绿了。需要重构吗?可以考虑接下来要解析布尔型的任务。布尔型不能“吃”参数值,也就是说目前抽取参数值的这部分代码,不能无条件执行,而是要根据当前参数标志所反映的规则类型来确定。所以我们需要把找规则的代码移动到“吃”参数值的前面。
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let tokens = commandLine.split(' ').filter(t => t.length);
while (tokens.length) {
let flag = tokens.shift().substring(1);
let schema = this.schemas.find(s => s.flag === flag);
let value = tokens.shift();
let arg = args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
return new Arguments(args);
}
保存,仍然是绿的。好了,开始下一个任务,“处理 2 个布尔型的参数”。先来一个失败的测试:
it('处理 2 个布尔型的参数', () => {
let schemas = [BooleanSchema('d'), BooleanSchema('e')];
let parser = new ArgumentParser(schemas);
let result = parser.parse('-d -e');
expect(result.get('d')).toEqual(true);
expect(result.get('e')).toEqual(true);
});
保存,红了。注意看出错提示,里面有告诉你是哪一行测试出的错。可以看到,是第二个 expect 的条件没有被满足。因为处理第一个参数的时候,就把第二个参数的标志当做第一个参数的值,给“吃”掉了。修正也很简单,加个判断就好了,只需要改一行:
let value = schema.type === BooleanArgumentType ? undefined : tokens.shift();
保存,绿了。需要重构吗?刚刚这一行其实就有需要重构的地方。这行是根据参数类型,决定是否“吃”规则参数值。而这实际上是参数类型本身的逻辑,或者说只和参数类型有关,而不应该放在规则解析器里面。所以我们把它挪到 BooleanArgumentType 里面:
export class ArgumentType {
static needValue() {
return true;
}
}
export class BooleanArgumentType extends ArgumentType {
static default() {
return false;
}
static convert() {
return true;
}
static needValue() {
return false;
}
}
对应的 parse() 方法:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let tokens = commandLine.split(' ').filter(t => t.length);
while (tokens.length) {
let flag = tokens.shift().substring(1);
let schema = this.schemas.find(s => s.flag === flag);
let value = schema.type.needValue() ? tokens.shift() : undefined;
let arg = args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
return new Arguments(args);
}
保存,绿的。这个方法越来越复杂了,早就看这个方法不顺眼了,我们来重构它。不要去看实现,直接从业务角度看,这个方法其实只干两件事情:根据默认值创建参数列表;解析命令行用传入值覆盖默认值。所以我们连续使用两次抽取方法(记得每次抽取之后都要保存跑测试):
parse(commandLine) {
let args = this.createDefaultArguments();
this.parseCommandLine(commandLine, args);
return new Arguments(args);
}
parseCommandLine(commandLine, args) {
let tokens = commandLine.split(' ').filter(t => t.length);
while (tokens.length) {
let flag = tokens.shift().substring(1);
let schema = this.schemas.find(s => s.flag === flag);
let value = schema.type.needValue() ? tokens.shift() : undefined;
let arg = args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
}
createDefaultArguments() {
return this.schemas.map(schema => this.getDefaultValue(schema));
}
把 args 到处传来传去也很烦,可以把它作为我们解析器的一个内部状态(属性):
parse(commandLine) {
this.createDefaultArguments();
this.parseCommandLine(commandLine);
return new Arguments(this.args);
}
parseCommandLine(commandLine) {
let tokens = commandLine.split(' ').filter(t => t.length);
while (tokens.length) {
let flag = tokens.shift().substring(1);
let schema = this.schemas.find(s => s.flag === flag);
let value = schema.type.needValue() ? tokens.shift() : undefined;
let arg = this.args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
}
createDefaultArguments() {
this.args = this.schemas.map(schema => this.getDefaultValue(schema));
}
保存,绿的。再看 parseCommandLine() 方法,它干了两件事:把 commandLine 拆分成 tokens,以及解析 tokens 中的内容。所以我们把这两个职责分开:
parse(commandLine) {
this.createDefaultArguments();
this.tokenizeCommandLine(commandLine);
this.parseTokens();
return new Arguments(this.args);
}
parseTokens() {
while (this.tokens.length) {
let flag = this.tokens.shift().substring(1);
let schema = this.schemas.find(s => s.flag === flag);
let value = schema.type.needValue() ? this.tokens.shift() : undefined;
let arg = this.args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
}
tokenizeCommandLine(commandLine) {
this.tokens = commandLine.split(' ').filter(t => t.length);
}
保存,绿的。嗯,现在 parse() 方法看起来很清爽了。接下来我们关注另外两个方法。可以看到一堆对 tokens 的使用:拆开,取出参数标志,取出参数值。既然它们都和 token 有关,那么就应该被放到一个与 token 有关的,独立的类里面。先直接在该文件中创建一个新类:
class Tokenizer {
constructor(commandLine) {
this.tokens = commandLine.split(' ').filter(t => t.length);
}
}
保存,绿的。为了实现平滑替换,我们需要看看,使用 tokens 的地方,用到了它的哪些属性和方法。目前看来,只有 parseTokens() 方法里面会用到,分别是 length 属性和 shift() 方法。我们先用最直接的方式实现它们(在 Tokenizer 类里面):
get length() {
return this.tokens.length;
}
shift() {
return this.tokens.shift();
}
保存,还是绿的。然后修改 tokenizeCommandLine() 方法:
tokenizeCommandLine(commandLine) {
this.tokens = new Tokenizer(commandLine);
}
保存,绿的。我们已经把 tokens 由原生数组对象,成功替换为我们的 Tokenizer 类的对象了。继续重构。看看 parseTokens() 里面的 while 语句,判断 tokens 的长度,用于决定是否继续循环。这个判断不是很有描述性,我们为 Tokenizer 类加一个新方法。既然是用于判断是否还有更多的 token,那么就命名为 hasMore() 吧:
hasMore() {
return this.tokens.length > 0;
}
保存,绿的。然后修改 parseTokens() 里面的 while 的条件判断:
while (this.tokens.hasMore()) {
// ...
}
保存,绿的。现在 Tokenizer.length 属性已经没有地方用到了,IDE 也会自动将这个属性名标记为灰色。我们直接删除掉这个属性定义即可。保存,还是绿的。接下来是两处 shift() 调用,分别用于取出标志和值。先处理取标志。通常这种在循环里面,一个一个取的动作,我们称之为 next。那么取出一个标志,就命名为 nextFlag()。为 Tokenizer 类加入该方法:
nextFlag() {
return this.tokens.shift().substring(1);
}
保存,绿的。修改第一处对 tokens.shift() 的调用:
let flag = this.tokens.nextFlag();
保存,还是绿的。然后是用于取值的那个 tokens.shift() 调用,取出值就是 nextValue()。同样加入 Tokenizer 类:
nextValue() {
return this.tokens.shift();
}
保存,绿的。修改第二处对 tokens.shift() 的调用:
let value = schema.type.needValue() ? this.tokens.nextValue() : undefined;
保存,绿的。可以看到,Tokenizer.shift() 方法也被 IDE 标记为灰色了,因为我们也没有再用它了。删除该方法,保存,绿的。至此,我们的 Tokenizer 初步完成了,跟 token 相关的逻辑都封装到这个类里面了。于是我们 F6,把它搬移到属于它自己的文件里面吧,文件名是 main/tokenizer.js。
再看 parseTokens() 方法:
parseTokens() {
while (this.tokens.hasMore()) {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(s => s.flag === flag);
let value = schema.type.needValue() ? this.tokens.nextValue() : undefined;
let arg = this.args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
}
它还是干的两件事情,一个是做循环,一个是处理当前取出来的参数。于是,我们可以把循环的内容单独抽取出来:
parseTokens() {
while (this.tokens.hasMore()) this.parseToken();
}
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(s => s.flag === flag);
let value = schema.type.needValue() ? this.tokens.nextValue() : undefined;
let arg = this.args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
保存,绿的。这下 parseTokens() 方法也很清爽了。接着我们关注 parseToken() 方法。可以看到 let value = ... 这行有些长,而且里面包含逻辑,我们把它抽取出来,就叫 nextValue() 吧:
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(s => s.flag === flag);
let value = this.nextValue(schema);
let arg = this.args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
nextValue(schema) {
return schema.type.needValue() ? this.tokens.nextValue() : undefined;
}
保存,绿的。再看 parseToken 的最后一行,对 value 做类型转换,也应该是属于 nextValue() 的一部分:
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(s => s.flag === flag);
let value = this.nextValue(schema);
let arg = this.args.find(a => a.flag === flag);
arg.value = value;
}
nextValue(schema) {
let value = schema.type.needValue() ? this.tokens.nextValue() : undefined;
return schema.type.convert(value);
}
保存,绿的。可以看到 nextValue() 里面并没有直接使用传进来的 schema,而是全程使用 schema.type,既然如此,直接传 type 进来就好了:
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(s => s.flag === flag);
let value = this.nextValue(schema.type);
let arg = this.args.find(a => a.flag === flag);
arg.value = value;
}
nextValue(type) {
let value = type.needValue() ? this.tokens.nextValue() : undefined;
return type.convert(value);
}
保存,绿的。这下 parseToken() 里面的 value 变量就没有存在的必要了。选中 value 的定义,敲 Ctrl + Alt + N/Cmd + Alt + N 内联变量:
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(s => s.flag === flag);
let arg = this.args.find(a => a.flag === flag);
arg.value = this.nextValue(schema.type);
}
保存,还是绿的。继续看 parseToken() 方法,两个 find() 调用显得比较扎眼。其中,schemas.find() 括号里面的逻辑,应该是规则列表的逻辑,解析器本身不需要关注这个。同理,args.find() 括号里面的逻辑,则应该是参数列表的逻辑,解析器也不需要关心。这说明我们需要一个 Schemas 类,用于处理规则列表相关的逻辑,和一个 Arguments 类,用于处理参数列表逻辑。而后者我们已经有了,所以先处理这个,对,这样难度更低。
处理方式前面已经介绍过了。先看看目前使用了 args 的哪些属性和方法。发现只用到了其 find() 方法。那就先为 Arguments 类新增一个 find() 方法:
find(cb) {
return this.items.find(cb);
}
保存,绿的。替换 ArgumentParser.createDefaultArguments() 方法中 args 的创建方式:
createDefaultArguments() {
this.args = new Arguments(this.schemas.map(schema => this.getDefaultValue(schema)));
}
别忘了同时修改 parse() 方法中的返回值:
parse(commandLine) {
this.createDefaultArguments();
this.tokenizeCommandLine(commandLine);
this.parseTokens();
return this.args;
}
保存,绿的。于是我们可以修改 Arguments.find() 方法:
find(flag) {
return this.items.find(item => item.flag === flag);
}
同时替换 ArgumentParser.parseToken() 中调用的那一行:
let arg = this.args.find(flag);
保存,绿的。接下来轮到规则列表,这个类还没有,于是我们就在 ArgumentParser 类所在的文件中创建这个新类:
class Schemas {
constructor(items) {
this.items = items;
}
}
保存,绿的。老办法,替换之前,看看目前用到了 schemas 的哪些属性和方法。可以看到,目前就用到 map() 和 find() 两个方法。先做直接传递,为 Schemas 类添加两个方法:
find(cb) {
return this.items.find(cb);
}
map(cb) {
return this.items.map(cb);
}
保存,还是绿的。修改 ArgumentParser 构造函数的实现:
constructor(schemas) {
this.schemas = new Schemas(schemas);
}
保存,绿的。类的替换完成了,可以开始方法的替换了。其中 find() 方法比较简单,和前面的 Arguments 一样的。修改 Schemas.find() 方法:
find(flag) {
return this.items.find(item => item.flag === flag);
}
同时替换 ArgumentParser.parseToken() 中调用的那一行:
let schema = this.schemas.find(flag);
保存,绿的。接下来看看 createDefaultArguments() 方法。看起来,该方法对 schemas 的使用,与解析器并没有任何关系,我们应该可以把相应的实现都移动到 Schemas 类里面。不过这样会导致另一个问题,那就是我们会在 Schemas 类中创建 Argument 类的对象。从设计角度看,参数信息和规则信息并没有直接的关系,让它们相互依赖是不合理的。于是协调两者这种“粗重活”就落到了我们的解析器身上。也就是说这里的 schemas.map() 挪不走了。不过为了简化调用,还是有一点改进空间的。先修改 Schemas.map() 方法:
map(cb) {
return this.items.map(item => cb(item));
}
然后修改 createDefaultArguments() 的实现:
createDefaultArguments() {
this.args = new Arguments(this.schemas.map(this.getDefaultValue));
}
保存,绿的。嗯,比之前省了四分之一的长度。这个 getDefaultValue() 感觉不是很贴切了,它的作用其实就是创建对应的 Argument,使用默认值只是创建它的实现逻辑。所以我们用 Shift + F6 将其改名为 createArgument。保存,还是绿的。
再看看现在的 parseToken():
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(flag);
let arg = this.args.find(flag);
arg.value = this.nextValue(schema.type);
}
后两行,把 arg 找出来,再给它赋值,其实可以一步完成的,没有必要分成两步,何况 arg 后面也只用了这一次。为 Arguments 新增 set() 方法:
set(flag, value) {
this.find(flag).value = value;
}
保存,绿的。修改 parseToken():
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(flag);
this.args.set(flag, this.nextValue(schema.type));
}
保存,绿的。感觉仍然不是很爽,nextValue() 的两个参数一个是使用变量,一个是调用方法,看起来不一致。选中第二个参数,敲 Ctrl + Alt + V/Cmd + Alt + V 抽取变量,命名为 value:
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(flag);
let value = this.nextValue(schema.type);
this.args.set(flag, value);
}
保存,绿的。Ok,这个方法也清爽了。刚才修改 Arguments 类的时候看到 get() 和 find() 方法存在重复代码:
find(flag) {
return this.items.find(item => item.flag === flag);
}
get(flag) {
return this.items.find(item => item.flag === flag).value;
}
很明显,让 get() 直接使用 find() 就可以了:
get(flag) {
return this.find(flag).value;
}
保存,绿的。接下来,把 Schemas 类移动到新建的 main/schemas.js 文件里面,保存,绿的。
现在,我们的 ArgumentParser 就是这个样子:
import { Arguments } from './arguments';
import { Argument } from './argument';
import { Tokenizer } from './tokenizer';
import { Schemas } from './schemas';
export class ArgumentParser {
constructor(schemas) {
this.schemas = new Schemas(schemas);
}
parse(commandLine) {
this.createDefaultArguments();
this.tokenizeCommandLine(commandLine);
this.parseTokens();
return this.args;
}
createDefaultArguments() {
this.args = new Arguments(this.schemas.map(this.createArgument));
}
createArgument(schema) {
return new Argument(schema.flag, schema.type.default());
}
tokenizeCommandLine(commandLine) {
this.tokens = new Tokenizer(commandLine);
}
parseTokens() {
while (this.tokens.hasMore()) this.parseToken();
}
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(flag);
let value = this.nextValue(schema.type);
this.args.set(flag, value);
}
nextValue(type) {
let value = type.needValue() ? this.tokens.nextValue() : undefined;
return type.convert(value);
}
}
好了,拆出来的两个小需求也做完了,继续拆吧。两个参数类型一致的情况已经覆盖到了,接下来自然是类型不一致的情况。那么,一个整型和一个字符串型,有必要吗?没有,在类型转换已经覆盖到了的情况下,一个整型和一个字符串型,跟两个整型,没有区别。所以,最好是需要参数值和不需要参数值的组合。整型加布尔型,以及布尔型加整型:
- 处理 2 个参数
处理 2 个整数型的参数处理 2 个布尔型的参数- 处理 1 个整型和 1 个布尔型的参数
- 处理 1 个布尔型和 1 个整型的参数
好,来个失败的测试:
it('处理 1 个整型和 1 个布尔型的参数', () => {
let schemas = [IntegerSchema('p'), BooleanSchema('d')];
let parser = new ArgumentParser(schemas);
let result = parser.parse('-p 8080 -d');
expect(result.get('p')).toEqual(8080);
expect(result.get('d')).toEqual(true);
});
保存,红……咦?怎么没变红,还是绿的?因为……哈哈,恭喜你,这个需求已经完成了。无论你信不信,虽然我们搞了很多假实现和傻实现,而且每一步都小得很娘炮,不过,我们确实已经把参数解析的正常业务逻辑做完了。
那么问题来了,这个测试还有没有必要保留呢?当然有了,测试可以用来驱动实现,这是其重要作用之一,但不是全部。用来验证需求,充当安全网,才是其最根本的作用。虽然这个需求所要求的实现代码,已经被前面的测试覆盖到了。但是,这是基于我们目前的实现方式,指不定以后哪天,另一位同学接手这份代码,来了一个大大的“重构”,恰好能通过前面的所有测试,但是无法通过这个测试呢?那它就帮助我们避免了一个 bug。
有同学要问了,如果按照这个逻辑,那我们还可以再写 100 个测试,怎样才算完呢?这是个好问题,目前业界对此的答案是:“看信心”。也就是说,写到——你认为覆盖到了足够多的情况,因而不会出错了——为止。哈哈,这听起来有点玄学的味道。不过也还是有迹可循的,通常,把主要业务逻辑、异常情况覆盖到以后,再加上一些边界条件的测试,基本上就差不多了。这些都有了,就可以自由发挥了,不过别发挥太多就好。
所以,新加的这两个小任务,是属于“自由发挥”的吗?你猜呢?:)其实不是的,这是我们在覆盖边界条件。虽然我们的实现逻辑是一次“吃”一个 token,但不排除将来想要做重构的同学修改这个实现方式。如果有人“聪明”的提前把拆出来的 token 两两分组,以方便进一步处理,那就会在处理布尔型参数的时候遇到问题。所以,把需要参数值的(整型、字符串型)参数,和不需要参数值的(布尔型)参数混排,就是用来覆盖这个边界条件的。
说到这里,其实还有一个边界条件我们没有覆盖的,那就是我们没有针对整型参数的传值是负数的情况进行测试。为什么这是一个边界条件?首先,对于整数而言,正数、零、负数,都是属于边界条件(用测试语言说,叫做等价类 [6])。其次,负数的负号,和我们参数标志前面的“杠”,是同一个字符。所以如果将来有同学做重构,把拆分命令行的现有代码实现,改为用正则表达式进行匹配拆分,就有可能把负数前面的负号给吃掉。所以,负数也是需要覆盖到的,我们后面找个用例顺便覆盖一下就好了。
那么,我们可以开始下一个小任务了吗?别急,注意看测试代码,第二颗子弹已经来了。三个新的测试用例,一如既往的充斥着重复代码,仍然需要抽取公共方法。手法都是前面介绍过的,这里就不展开了,直接看重构结果。公共方法:
function testMultipleArguments(schemaTypes, flags, commandLine, expectedValues) {
let schemas = schemaTypes.map((schemaType, i) => schemaType(flags[i]));
let parser = new ArgumentParser(schemas);
let result = parser.parse(commandLine);
expectedValues.forEach(
(expectedValue, i) => expect(result.get(flags[i])).toEqual(expectedValue),
);
}
测试用例:
it('处理 2 个整数型的参数', () => {
testMultipleArguments([IntegerSchema, IntegerSchema], ['p', 'q'],
'-p 8080 -q 9527', [8080, 9527]);
});
it('处理 2 个布尔型的参数', () => {
testMultipleArguments([BooleanSchema, BooleanSchema], ['d', 'e'],
'-d -e', [true, true]);
});
it('处理 1 个整型和 1 个布尔型的参数', () => {
testMultipleArguments([IntegerSchema, BooleanSchema], ['p', 'd'],
'-p 8080 -d', [8080, true]);
});
保存,绿的。重复代码是没有了,不过测试用例里面的代码看起来还是很诡异啊。传给 testMultipleArguments() 的的参数一共四个,其中第一第二和第四个都是数组,第三个是字符串。这个调用看起来很不直观,而越不直观的代码,维护起来越困难,而且还容易出错。那怎么改呢?可以看到传的三个数组其实是一一对应的,所以我们可以把三个数组合并为一个数组。引入一个简单对象作为数组的成员,这个对象包含三个属性,分别代表之前的三个数组的含义:规则类型、参数标志以及期待值。调整之后的公共方法:
function testMultipleArguments(commandLine, params) {
let schemas = params.map(param => param.type(param.flag));
let parser = new ArgumentParser(schemas);
let result = parser.parse(commandLine);
params.forEach((param) => {
let { flag, value } = param;
expect(result.get(flag)).toEqual(value);
});
}
测试用例:
it('处理 2 个整数型的参数', () => {
testMultipleArguments('-p 8080 -q 9527', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: IntegerSchema, flag: 'q', value: 9527 },
]);
});
it('处理 2 个布尔型的参数', () => {
testMultipleArguments('-d -e', [
{ type: BooleanSchema, flag: 'd', value: true },
{ type: BooleanSchema, flag: 'e', value: true },
]);
});
it('处理 1 个整型和 1 个布尔型的参数', () => {
testMultipleArguments('-p 8080 -d', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: BooleanSchema, flag: 'd', value: true },
]);
});
保存,绿的。这下测试用例看起来清楚多了。接下来需要把三个公共函数也整理一下。首先,testSingleArgument() 很显然是属于 testMultipleArguments() 的特殊情况,直接调用即可省掉重复代码:
function testSingleArgument(schemaType, flag, commandLine, expectedValue) {
testMultipleArguments(commandLine, [
{ type: schemaType, flag, value: expectedValue },
]);
}
保存,绿的。既然这个方法只是一个二传手,不如直接把它干掉,还能省下不少代码。光标定位到 testSingleArgument() 的定义处,敲 Ctrl + Alt + N/Cmd + Alt + N 内联函数。干掉一个了。接下来看看 testDefaultValue(),同样也只是个二传手,照样把它也给内联了吧。最后公共方法就只剩下了 testMultipleArguments() 这一个了。在没有另外两个公共方法(的名字)的“衬托”下,这个名字就不是很贴切了。咱们 F6,给它改成 testParse() 吧,于是测试用例部分的代码就变成了:
describe('ArgumentParser', () => {
describe('处理默认参数', () => {
it('处理布尔型参数的默认值', () => {
testParse('', [
{ type: BooleanSchema, flag: 'd', value: false },
]);
});
it('处理字符串型参数的默认值', () => {
testParse('', [
{ type: StringSchema, flag: 'l', value: '' },
]);
});
it('处理整数型参数的默认值', () => {
testParse('', [
{ type: IntegerSchema, flag: 'p', value: 0 },
]);
});
});
describe('处理 1 个参数', () => {
it('处理布尔型参数', () => {
testParse('-d', [
{ type: BooleanSchema, flag: 'd', value: true },
]);
});
it('处理字符串型参数', () => {
testParse('-l /usr/logs', [
{ type: StringSchema, flag: 'l', value: '/usr/logs' },
]);
});
it('处理整数型参数', () => {
testParse('-p 8080', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
]);
});
});
describe('处理 2 个参数', () => {
it('处理 2 个整数型的参数', () => {
testParse('-p 8080 -q 9527', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: IntegerSchema, flag: 'q', value: 9527 },
]);
});
it('处理 2 个布尔型的参数', () => {
testParse('-d -e', [
{ type: BooleanSchema, flag: 'd', value: true },
{ type: BooleanSchema, flag: 'e', value: true },
]);
});
it('处理 1 个整型和 1 个布尔型的参数', () => {
testParse('-p 8080 -d', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: BooleanSchema, flag: 'd', value: true },
]);
});
});
});
保存,绿的。Neat!测试代码也很清楚吧。这份测试代码好维护吗?加入更多用例简单吗?不言而喻的吧。所以,如果有人说“由于 XXX 的原因,测试代码很难维护”(XXX 这个变量你随便填),你就知道了,这个同学不会做重构。
接下来可以加入下一个任务的测试了:
it('处理 1 个布尔型和 1 个整型的参数', () => {
testParse('-d -p 8080', [
{ type: BooleanSchema, flag: 'd', value: true },
{ type: IntegerSchema, flag: 'p', value: 8080 },
]);
});
保存,仍然是绿的,没毛病,说过嘛,已经实现了的。第三个大任务搞定,休息一下吧。
第四第五两个大任务
欢迎回来。有了前面的铺垫,剩下的工作就简单很多了。别误会,前面的工作也很简单,对吧,每个步骤都简单,是我们 TDD 的原则。只是由于大家应该已经熟悉 TDD 相关的流程了,所以,接下来,操作方面会讲得简单一些,而思考层面的内容,还是会一如既往进行详细的阐述。
接下来是“处理 3 个参数”这个大任务。这是属于正常业务逻辑,如前所述,正常的业务逻辑,我们都已经实现完了。再加上异常逻辑是由下一个大任务所覆盖的。所以,现在,我们只需要覆盖一些边界条件,加上一点点自由发挥,就可以了。
边界条件嘛,前面也讲过,我们把布尔型的放在中间,外面分别用整型和字符串型包裹,就是一个用例了。此外,前面说了,还需要覆盖负数,那我们就用一个负数,再把布尔型放在末尾。再来一个有传值和没传值混合的。嗯,差不多了:
- 处理 3 个参数
- 处理 1 个整型、1 个布尔型和 1 个字符串型参数
- 处理 1 个负数、1 个字符串型和 1 个布尔型参数
- 处理 1 个布尔型、1 个字符串型和 1 个未传的整型参数
写测试:
describe('处理 3 个参数', () => {
it('处理 1 个整型、1 个布尔型和 1 个字符串型参数', () => {
testParse('-p 8080 -d -s /usr/logs', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: BooleanSchema, flag: 'd', value: true },
{ type: StringSchema, flag: 's', value: '/usr/logs' },
]);
});
});
保存,绿的。下一个测试:
it('处理 1 个负数、1 个字符串型和 1 个布尔型参数', () => {
testParse('-q -9527 -s /usr/logs -d', [
{ type: IntegerSchema, flag: 'q', value: -9527 },
{ type: StringSchema, flag: 's', value: '/usr/logs' },
{ type: BooleanSchema, flag: 'd', value: true },
]);
});
保存,绿的。再下一个测试:
it('处理 1 个布尔型、1 个字符串型和 1 个未传的整型参数', () => {
testParse('-d -s /usr/logs', [
{ type: IntegerSchema, flag: 'p', value: 0 },
{ type: BooleanSchema, flag: 'd', value: true },
{ type: StringSchema, flag: 's', value: '/usr/logs' },
]);
});
保存,还是绿的,又完成一个大任务。看看生产代码有没有需要重构的,暂时没有。再看看测试代码有没有需要重构的,也没有。
我们可以开始下一个大任务了:“处理异常情况”。仍然是先拆任务。要处理异常情况,最好是先看看,异常情况是谁引入的。对,先把人(角色)找到,然后再从人的角度分析,有点类似用户画像,这样做比较不容易出现遗漏。对于我们这里的业务,引入异常的人可以分为两类:我们的用户,以及我们用户的用户。当然,还有我们自己,不过 TDD 的流程保证了,我们自己不会引入异常(否则测试无法通过),所以这里就不用考虑我们自己了。我们是写解析器的人,我们的用户,就是写应用程序(比如前面提到的“网络服务器程序”)的人。而我们用户的用户,就是使用那些应用程序的人。
我们的用户,可能引入哪些异常?首先,最好的方案自然是让他们没有机会引入异常。他们一旦使用上出现问题,IDE 或者编译器能告诉他们,那么就没有机会引入异常,这是最理想的。相应的设计,我们在前面沟通需求的地方已经讨论过了。当然,现实情况通常都不那么理想,所以,还是会异常需要处理的。我们的解析器类,一共有两个输入参数,一个是规则定义,一个是命令行。这两个参数都有可能引入异常。
由于我们这里用的 JavaScript 是动态类型的语言,所以会有一个共性的问题:类型安全问题。我们的规则参数是接收一个 Schema 的数组,要是人家传过来的不是数组呢?要是数组里面的元素不是 Schema 的实例呢?如果创建规则的时候,传进去的 flag 的长度不是一个字符呢?如果传进来的命令行不是一个字符串呢(记得我们对它调用了 split() 方法吧)?
虽然这些问题对应静态类型的语言(比如 TypeScript、Java)都不是问题,不过,嘿,面对现实。如果你想写一个靠谱的第三方组件,那么这些情况是必须要考虑的。插播一个暴露年龄的段子:屏幕上有一行提示:“请用鼠标点击这里开始”,于是用户抓起鼠标,轻轻的在了屏幕左下角敲了一下。这个故事告诉我们,当你考虑异常情况的时候,一定要假设你的用户都是白痴!否则,今天挖的坑,将来都是要填的,也许是你相亲那天,也许是某天凌晨两点四十二分三十九秒,谁知道呢。
所以,你知道了,如果哪天你发现一个特别好用的软件,那么其实你已经……被他们白痴了无数次了:)
由于类型安全处理的实现非常简单,并且 Java 的同学也用不上,考虑到篇幅问题,我们就不在本文中做展开了。有兴趣的同学,可以把这个当做练习题。
再看我们用户的用户,他们可能引入哪些异常?谢天谢地,他们只能影响我们的 commandLine 这个参数的内容。想想他们的使用场景,他们只是在命令行里,敲击键盘,启动由我们的用户所制作的软件。没有 IDE 的协助,敲错字母是很常见的情况吧。比如,本来要敲 -v 的,手一抖,就敲成了 -b,而我们的用户(应用程序的开发者),压根就没有定义 b 这个规则。于是,我们的第一个任务就有了:
- 处理异常情况
- 处理规则未定义的情况
既然标志可能敲错,那么值也有可能敲错。字符串型的值是不怕错的,布尔型本来就没有值,所以,最常见的是整型的值敲错了,比如一不小心混了个字母进去。这就是第二个任务了:
- 处理异常情况
- 处理规则未定义的情况
- 处理整型参数的值不合法的情况
刚才说“布尔型本来就没有值”,可别轻易放过了,这也有可能引入异常的哦。对呀,不该传值的时候,传了值进来,也是问题:
- 处理异常情况
- 处理规则未定义的情况
- 处理整型参数的值不合法的情况
- 处理传了多余的值的情况
既然有多传值的情况,就可能有少传值的情况:
- 处理异常情况
- 处理规则未定义的情况
- 处理整型参数的值不合法的情况
- 处理传了多余的值的情况
- 处理字符串型参数没有传值的情况
嗯,任务拆得差不多了,可以开始编码了。在做第一个小任务之前,还得先细化一下,这个用例怎么写。命令行里面传入一个 -b,而规则列表为空,就可以了,这样最简单。一旦解析器发现这个问题,就应该抛出一个异常,以提醒我们的用户。还有一个很重要的事情,就是异常信息(出错提示)的选择。时刻记住,用户角度,你的这个信息,必须对用户修正问题有足够的帮助。要是你只给个“出错啦”一类的信息,用户会来薅你头发,你信么:)所以,这里既然是参数未定义的问题,就一定要清楚的告知用户,某某参数是未定义的。
先来一个失败的测试:
describe('处理异常情况', () => {
it('处理规则未定义的情况', () => {
let schemas = [];
let parser = new ArgumentParser(schemas);
let commandLine = '-b';
expect(() => parser.parse(commandLine)).toThrow('Unknown flag: -b');
});
});
保存,红的。注意,这里出现一个新用法:expect(fn).toThrow(error)。就是执行 fn 这个函数的时候,必须出现包含 error 信息的异常。如果没有出现异常,或者出现的异常中不包含 error 所指明的信息,测试就会不通过。注意,只能传函数的名字进去,随后 expect() 会帮我们执行这个函数,并自动截获相应的异常。所以我们这里使用了一个匿名函数,因为你没法直接给这个函数传递参数。如果你写 expect(parser.parse(commandLine)),那就是把函数调用的结果(Arguments,而非函数本身)传给 expect() 了。而你的 parse() 一旦出现异常,expect() 就没有机会执行了(因为执行一个函数之前,得先把它需要的参数全部准备好,如果在准备参数的过程中出现异常,那么这个函数是没有机会执行的),它也就没有机会帮你捕获这个异常了。
此外,前面不是说出错提示是“未定义”吗,怎么这里用的“Unknown”(未知)呢?主要是考虑到,用户有可能直接把这个出错提示展示给他们的用户。那么“未知”这个说法,对用户的用户会更友好一些。还记得吧,用户视角。
好,我们尽快让它通过。逻辑很简单,通过标志去找规则的时候,如果找不到就抛出异常。修改 Schemas.find() 方法,选中 return 之后的内容,Ctrl + Alt + V/Cmd + Alt + V抽取变量,命名为 found,然后中间加入一行判断即可:
find(flag) {
let found = this.items.find(item => item.flag === flag);
if (!found) throw new Error(`Unknown flag: -b`);
return found;
}
保存,绿了。重构,很明显,为了快速通过测试,我们的出错提示是写死的,现在把它写活:
if (!found) throw new Error(`Unknown flag: -${flag}`);
保存,绿的。下一个:“处理整型参数的值不合法的情况”。先假装不会有其他问题,主要还是关注出错提示的合理性。失败的测试:
it('处理整型参数的值不合法的情况', () => {
let schemas = [IntegerSchema('p')];
let parser = new ArgumentParser(schemas);
let commandLine = '-p 123a';
expect(() => parser.parse(commandLine)).toThrow('Invalid integer: 123a');
});
保存,红了。不过,注意看出错提示,红归红,不是我们期待的出错信息不正确的红,而是“Received function did not throw”,即指定方法并未抛出异常。这里就要了解我们的实现了,我们用了 parseInt() 对字符串进行解析。而这个工具函数,有一定的包容性,你传 '123a456' 给它,它能给你吐出 123 来;如果给它 'a456',则会返回给你 NaN。所以,数字合法性得我们自己来进行验证,方法也很简单,上个正则就搞定了。那么判断放在哪里呢?自然是放在对应的 IntegerArgumentType.convert() 里面了,它负责类型转换嘛。还记得吧,要快速通过,所以我们依葫芦画瓢,提示信息先继续写死:
static convert(value) {
if (!value.match(/^[-]?\d+$/)) throw new Error(`Invalid integer: 123a`);
return parseInt(value, 10);
}
保存,绿了。重构出错提示:
if (!value.match(/^[-]?\d+$/)) throw new Error(`Invalid integer: ${value}`);
保存,仍然是绿的。应该能记住这个节奏了吧,一定要快速变绿,然后重构。现在够好了没?不,还不够。我们再看看这个出错提示:“Invalid integer: 123a”,设想一下,如果你是我们用户的用户。你现在要启动一个程序,传了一堆参数,其中某一个参数的值出错了,如果手上只有这个信息,能不能帮助你快速定位到问题并修正?能帮你找到信息,但是,如果要快,那么应该有更丰富的信息。很显然,参数值和参数标志是成对出现的,如果不仅有参数值,而且还有参数标志,可以帮助我们用户的用户更加方便的找到出问题的地方,并进行修正。
按照这个思路,我们修改一下测试:
expect(() => parser.parse(commandLine)).toThrow('Invalid integer of flag -p: 123a');
保存,红了。好,让它快速通过:
if (!value.match(/^[-]?\d+$/)) throw new Error(`Invalid integer of flag -p: ${value}`);
保存,绿了。接下来重构它。我们看到,需要的这个 -p,我们的 convert() 方法是没有的,需要从外面传进来。哟,要改接口,这得要花一袋烟的功夫吧。为了改个出错提示,这么折腾,值得吗?值得!为了让用户方便,我们自己麻烦一点点,是值得的,让用户方便正是我们存在的价值嘛。何况我们有测试保驾护航,怕个毛线啊,随便改:)先修改 ArgumentParser,把 flag 一路传进 convert():
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(flag);
let value = this.nextValue(schema.type, flag);
this.args.set(flag, value);
}
nextValue(type, flag) {
let value = type.needValue() ? this.tokens.nextValue() : undefined;
return type.convert(value, flag);
}
保存,还是绿的。接着修改 IntegerArgumentType.convert():
static convert(value, flag) {
if (!value.match(/^[-]?\d+$/)) throw new Error(`Invalid integer of flag -${flag}: ${value}`);
return parseInt(value, 10);
}
保存,绿的。下一个:“处理传了多余的值的情况”。来个失败的测试:
it('处理传了多余的值的情况', () => {
let schemas = [BooleanSchema('d')];
let parser = new ArgumentParser(schemas);
let commandLine = '-d hello';
expect(() => parser.parse(commandLine)).toThrow('Unexpected value: hello');
});
保存,红了。接下来让它通过。接下来需要稍微动点脑子,否则就算你想写假实现,都不知道该往哪里加。所谓“多余的值”,实际上就是,该“吃”的值吃完了,还剩下一个值在我们的 Tokenizer 里面。而值“吃”完了,接下来该吃什么?该“吃”标志了。所以,这个逻辑的处理,应该是在取标志的时候进行。而多余的值,和一个正常的标志,两者之间的区别,就是它是否以 '-' 开头。所以,我们修改 Tokenizer.nextFlag() 方法,选中 this.tokens.shift(),抽取变量,命名为 token。再在中间加入一行判断:
nextFlag() {
let token = this.tokens.shift();
if (!token.startsWith('-')) throw new Error(`Unexpected value: hello`);
return token.substring(1);
}
保存,绿了。重构,把出错提示写活:
if (!token.startsWith('-')) throw new Error(`Unexpected value: ${token}`);
保存,还是绿的。接下来还有什么需要重构的?注意,这是我们连续做的第三个小任务,所以,出现“第二颗子弹”的几率会比较大。先看出错信息,我们三个任务,用到三次 throw new Error(),而且竟然分布在三个不同的文件里面。同样是出错信息,统一管理起来肯定是有好处的,比如要做多语言,要写文档等等。所以,我们需要把这些错误信息归置归置。那么,只需要抽取三个字符串常量出来就可以了吗?当然是可以的,不过,为了让使用的地方更简洁一些,我们可以把整个异常一起抽取出来。
来到 Schemas.find() 方法,选中从 throw 开始一直到行尾,抽取一个全局的方法,命名为 unknownFlagError:
function unknownFlagError(flag) {
throw new Error(`Unknown flag: -${flag}`);
}
而 find() 中调用那一行则变为了:
if (!found) unknownFlagError(flag);
保存,绿的。这样看起来更清楚一些。接着我们 F6 把这个新抽取出来的方法,移动到新建的 main/errors.js 文件中,保存,绿的。
同样的手法,我们从 IntegerArgumentType.convert() 中抽取出 invalidIntegerError(),并将其移入刚才创建的 errors.js 文件中。记得保存并确保仍然是绿的。最后是从 Tokenizer.nextFlag() 中抽取出 unexpectedValueError(),并同样移入 errors.js 文件。保存,仍然是绿的。现在 errors.js 文件长这个样子:
export function unknownFlagError(flag) {
throw new Error(`Unknown flag: -${flag}`);
}
export function invalidIntegerError(flag, value) {
throw new Error(`Invalid integer of flag -${flag}: ${value}`);
}
export function unexpectedValueError(token) {
throw new Error(`Unexpected value: ${token}`);
}
把它们归集到一起,其实还有一个好处。现在三个函数都是直接抛出的 Error 类的实例,它们之间的区别仅仅在于消息字符串的不同。仍然考虑用户视角,这其实是不友好的。为什么?想象一下,如果我们的用户,需要根据不同的错误,做一些不同的逻辑处理,他们应该如何判断当前出现的是哪种错误呢?只能根据错误中的消息字符串进行判断。而消息字符串是不稳定的,毕竟是描述性的信息嘛,哪天产品经理一句话,就改了;或者做了多语言,翻译成别的语言了。因此,依赖于消息字符串,是不可靠的。为了给用户提供这方面的方便,应该怎么做呢?
至少有三种办法:
- 为错误对象新增一个整数型的错误编码属性(这个整型编码是稳定的)
- 每个错误使用不同的类(并且通常它们会有共同的父类,以便于用户统一截获,然后分别处理)
- 可以结合 1 和 2 两种方式(不仅有不同的类,而且每个类上还也有错误编码属性)
所以,把他们归置在一起,要做这些修改,就会方便很多。不过,出于篇幅限制,这个话题我们也不展开了。同样的,如果有兴趣,可以把这个当做练习题。
重构完了吗?生产代码暂时是重构完了。别忘了同样重要的测试代码,新增的三个用例明显是有重复代码的。抽取公共方法,因为都是会抛出错误的,所以我们就命名为 testParsingError 吧。抽取手法前面已经详细介绍过了,这里就不重复了。抽取出来的公共方法:
function testParsingError(commandLine, schemas, error) {
let parser = new ArgumentParser(schemas);
expect(() => parser.parse(commandLine)).toThrow(error);
}
三个调整后的测试用例:
it('处理规则未定义的情况', () => {
testParsingError('-b', [
], 'Unknown flag: -b');
});
it('处理整型参数的值不合法的情况', () => {
testParsingError('-p 123a', [
IntegerSchema('p'),
], 'Invalid integer of flag -p: 123a');
});
it('处理传了多余的值的情况', () => {
testParsingError('-d hello', [
BooleanSchema('d'),
], 'Unexpected value: hello');
});
保存,绿的。重构完了吗?扫一眼测试代码,你觉得呢?要想保持代码不会腐化,必须随时保持警觉。有了新的公共方法 testParsingError() 之后,有没有觉得之前的公共方法 testParse() 这个名字已经不是很贴切了?既然新的方法是测试解析会出错的,那么之前的方法就应该称之为测试解析会成功的——testParsingSuccess()。用 Shift + F6 改一下名字,保存,还是绿的。
这下算是重构完了。下一个:“处理字符串型参数没有传值的情况”。老规矩,先上失败的测试:
it('处理字符串型参数没有传值的情况', () => {
testParsingError('-s', [
StringSchema('s'),
], 'Value not specified of flag -s');
});
保存,红了。接下来让它通过。直接修改 Tokenizer.nextValue() 还是很简单的,套路前面也都用过。不过这里也有一个小问题,为了准确的报告错误,我们需要把标志的信息传进来。所以,先修改 ArgumentParser.nextValue():
nextValue(type, flag) {
let value = type.needValue() ? this.tokens.nextValue(flag) : undefined;
return type.convert(value, flag);
}
然后是 Tokenizer.nextValue():
nextValue(flag) {
if (!this.tokens.length) throw new Error(`Value not specified of flag -s`);
return this.tokens.shift();
}
保存,绿了。重构字符串和报错方法,提取出 valueNotSpecifiedError():
function valueNotSpecifiedError(flag) {
throw new Error(`Value not specified of flag -${flag}`);
}
同样将其移动到 errors.js 文件里面,Tokenizer.nextValue() 就变成了:
nextValue(flag) {
if (!this.tokens.length) valueNotSpecifiedError(flag);
return this.tokens.shift();
}
保存,还是绿的。好了,这个大任务也完成了。看看有什么需要重构的吗?暂时没有找到。休息一下吧。
最后一个大任务
最后一个大任务,附加题:“处理列表型参数”。仍然是先做任务拆分。需求本身还是很清楚的,布尔型不需要参数,也就是说只剩下字符串列表和整数列表两种情况。先做哪种情况呢?原则还记得吧,先做简单的。哪种更简单呢?也介绍过了,字符串的更简单。所以,初始的任务列表就有了:
- 处理列表型参数
- 处理字符串型列表参数
- 处理整型列表参数
完了吗?任务拆分也是介绍过的,除了正常的业务逻辑,还有哪些?异常情况、边界条件,再加上自由发挥。一个一个来。列表型参数可能引入什么异常?一个是整数列表的解析同样会有数字合法性问题。还有别的吗?可能会有同学想到分隔符不合法。仔细想一下,我们肯定会按合法的分隔符做拆分,所以,不合法的分隔符会作为某一个值的一部分。而字符串可以接受任意值,即使里面混入了非法分隔符,那就属于语义层面的问题了,我们的解析器是无法分辨的,从而也就无法处理。而如果非法分隔符进入了整数值,那么同样会被我们的数字合法性检查排查出来。此外,还可以参考已有的异常情况,可以发现其他几种异常,和列表参数没有什么关系。于是我们加入这个异常处理任务:
- 处理列表型参数
- 处理字符串型列表参数
- 处理整型列表参数
- 处理整型列表参数数字不合法的问题
这个异常处理任务放在这个列表里,主要是行文方便。实际开发的时候,我们会把它放到前一个大任务“处理异常情况”里面,这样分类会更清楚。接下来是边界条件。命令行为空,能算一个吧,这其实也就是默认参数的情形。无论是整型列表,还是字符串型列表,默认值都应该是空数组。加入这两个任务:
- 处理列表型参数
- 处理字符串型列表参数
- 处理整型列表参数
- 处理整型列表参数数字不合法的问题
- 处理字符串型列表参数的默认值
- 处理整数型列表参数的默认值
同样的,在测试用例里面,我们会把这两个默认值相关的任务,加入第一个大任务“处理默认参数”里面。任务列表的拆分就差不多了,再审视一遍,顺序还可以再调整一下。还记得吧,先做实现难度最小的任务。哪个难度最低呢?自然是默认值相关的,对吧。我们更新一下:
- 处理列表型参数
- 处理字符串型列表参数的默认值
- 处理整数型列表参数的默认值
- 处理字符串型列表参数
- 处理整型列表参数
- 处理整型列表参数数字不合法的问题
考虑到这是最后一个大任务了,我们把整个任务列表放出来,给大家一个直观的感受(加粗的是我们刚刚新增的和列表相关的任务):
- 处理参数默认值
- 处理布尔型参数的默认值
- 处理字符串型参数的默认值
- 处理整数型参数的默认值
- 处理字符串型列表参数的默认值
- 处理整数型列表参数的默认值
- 处理 1 个参数
- 处理布尔型参数
- 处理字符串型参数
- 处理整数型参数
- 处理 2 个参数
- 处理 2 个参数
- 处理 2 个整数型的参数
- 处理 2 个布尔型的参数
- 处理 1 个整型和 1 个布尔型的参数
- 处理 1 个布尔型和 1 个整型的参数
- 处理 3 个参数
- 处理 1 个整型、1 个布尔型和 1 个字符串型参数
- 处理 1 个负数、1 个字符串型和 1 个布尔型参数
- 处理 1 个布尔型、1 个字符串型和 1 个未传的整型参数
- 处理异常情况
- 处理规则未定义的情况
- 处理整型参数的值不合法的情况
- 处理传了多余的值的情况
- 处理字符串型参数没有传值的情况
- 处理整型列表参数数字不合法的问题
- 处理列表型参数
- 处理字符串型列表参数
- 处理整型列表参数
好,开始我们的第一个任务:“处理字符串型列表参数的默认值”。失败的测试走起:
it('处理字符串型列表参数的默认值', () => {
testParsingSuccess('', [
{ type: StringListSchema, flag: 's', value: [] },
]);
});
保存,红了。提示 StringListSchema 未定义。创建这个函数,并将其移动到 main/schema.js 文件中:
export function StringListSchema(flag) {
return new Schema(flag, StringListArgumentType);
}
这下变成了 StringListArgumentType 未定义。创建这个类,并将其移动到 main/argument-type.js 文件中:
export class StringListArgumentType extends ArgumentType {
}
接下来为 StringListArgumentType 类加入默认值处理方法:
static default() {
return [];
}
保存,绿了,任务完成。然后是“处理整数型列表参数的默认值”。失败的测试:
it('处理整数型列表参数的默认值', () => {
testParsingSuccess('', [
{ type: IntegerListSchema, flag: 'i', value: [] },
]);
});
保存,红了。同样的手法,为其加入 IntegerListSchema() 方法的实现
export function IntegerListSchema(flag) {
return new Schema(flag, IntegerListArgumentType);
}
以及 IntegerListArgumentType 类的定义:
export class IntegerListArgumentType extends ArgumentType {
}
然后就是为 IntegerListArgumentType 类加入默认值方法:
static default() {
return [];
}
保存,绿了。接下来是“处理字符串型列表参数”,失败的测试:
describe('处理列表型参数', () => {
it('处理字符串型列表参数', () => {
testParsingSuccess('-s how,are,u', [
{ type: StringListSchema, flag: 's', value: ['how', 'are', 'u'] },
]);
});
});
保存,红了。提示 “type.convert is not a function”。于是我们为 StringListArgumentType 类加入 convert() 方法:
static convert(value) {
return ['how', 'are', 'u'];
}
保存,绿了。为了让测试快速通过,这里是写死的。接下来,把它写活。实现也很简单,就是按分隔符进行拆分就行了:
static convert(value) {
return value.split(',');
}
保存,还是绿的。有同学这里会有疑问了:“明明一行真代码就能搞定的事情,为啥非要写成一行假代码,然后再替换它?这不是脱了裤子放屁吗?”你说的没错,对于这个简单的场景,是的。不过别忘了,我们现在是在做练习,最重要的不是解决某个具体问题,而是养成一个正确的习惯。实际工作中,你不一定能遇到可以一行代码解决的问题,一旦你直接上手写真实现,就有可能因为各种问题导致测试无法通过。而在红色状态停留超过一定的时间,你就会陷入焦虑,并且状态下降。为了提高效率,避免焦虑,你应该熟练掌握这种方法,并养成习惯。
现在需要重构吗?暂时不用,把下一个任务做了再说。开始“处理整型列表参数”,失败的测试:
it('处理整型列表参数', () => {
testParsingSuccess('-i 1,-3,2', [
{ type: IntegerListSchema, flag: 'i', value: [1, -3, 2] },
]);
});
保存,红了。可以看到,这里我们用了一个负数,算是顺手覆盖一个边界条件。随时保持对边界条件的警觉,对于提升代码稳定性是有好处的,建议有意识的培养自己的这个习惯。接下来尽快让它通过,为 IntegerListArgumentType 类新增 convert() 方法:
static convert(value) {
return [1, -3, 2];
}
保存,绿了。重构:
static convert(value) {
return value.split(',').map(v => parseInt(v, 10));
}
保存,还是绿的。现在可以考虑重构的事情了。看看新增的两个 ArgumentType 的子类:StringListArgumentType 和 IntegerListArgumentType,它们之间有重复代码吗?嗯,default() 方法里面的重复代码是很容易看出来的。很显然,任何列表型参数的默认值,都应该是空列表。所以,这两个类应该有一个公共的父类,专门用来处理列表型参数里面那些共通的逻辑。于是我们创建这个新类:
export class ListArgumentType extends ArgumentType {
static default() {
return [];
}
}
export class StringListArgumentType extends ListArgumentType {
static convert(value) {
return value.split(',');
}
}
export class IntegerListArgumentType extends ListArgumentType {
static convert(value) {
return value.split(',').map(v => parseInt(v, 10));
}
}
保存,绿的。接下来还有需要重构的么?就在这段代码里面就有的,能看出来吗?嗯,两个 value.split(',') 很明显是重复的。那么把它们抽取出来就搞定了吗?其实单独抽取 split() 是治标不治本的。能找出表面上不重复,但实际逻辑是重复的代码,是一项重要技能,需要多练。给个提示,我们先稍微改写一下 StringListArgumentType.convert() 方法:
static convert(value) {
return value.split(',').map(v => v);
}
保存,还是绿的。然后我们把两个类的 convert() 里面的代码放在一起来观察:
return value.split(',').map(v => v);
return value.split(',').map(v => parseInt(v, 10));
能看到什么?map() 里面的代码有没有似曾相识的感觉?还记得前面提到的“复读机”不?是的,这 map() 里面的,其实就是每个具体参数类型的 convert() 逻辑。对吧。这从业务上也是能说通的:作用于整数型参数的所有逻辑,同样应该作用于整型列表参数(中的每个数字)。也就是说,这里除了 split() 是重复代码以外,map() 里面的,也是重复代码。所以,这里的重构,不仅仅是代码层面的抽取,而且是业务逻辑的梳理。
那么具体应该如何入手呢?这里比较复杂,我们一步一步来。首先将 StringListArgumentType.convert() 中的 map() 里面的代码抽取出来:
static convert(value) {
return value.split(',').map(v => this.convertItem(v));
}
static convertItem(v) {
return v;
}
保存,绿的。同样手法,抽取 IntegerListArgumentType 里面的代码:
static convert(value) {
return value.split(',').map(v => this.convertItem(v));
}
static convertItem(v) {
return parseInt(v, 10);
}
保存,绿的。现在可以看到,两个 convert() 的代码完全一致了,把它们移动到父类里面(这里其实是【Pull Members Up】重构手法,不过 IDE 支持不够好,所以我们手工来),ListArgumentType.convert():
static convert(value) {
return value.split(',').map(v => this.convertItem(v));
}
把 StringListArgumentType.convert() 和 IntegerListArgumentType.convert() 删除掉即可。保存,还是绿的。
接着修改 StringListArgumentType.convertItem(),让它直接使用 StringArgumentType 的已有逻辑:
static convertItem(v) {
return StringArgumentType.convert(v);
}
保存,绿的。同样处理 IntegerListArgumentType.convertItem():
static convertItem(v) {
return IntegerArgumentType.convert(v);
}
保存,绿的。现在选中 StringListArgumentType 里面的 StringArgumentType,抽取方法,命名为 itemClass:
static convertItem(v) {
return this.itemClass().convert(v);
}
static itemClass() {
return StringArgumentType;
}
保存,绿的。同样手法处理 IntegerListArgumentType:
static convertItem(v) {
return this.itemClass().convert(v);
}
static itemClass() {
return IntegerArgumentType;
}
保存,绿的。现在两个 convertItem() 又是完全一致了,用刚才介绍的手法,把这个方法也上拉到父类 ListArgumentType 里面:
static convertItem(v) {
return this.itemClass().convert(v);
}
保存,绿的。这里的 v 这个名字不太好,Shift + F6 改名为 value,保存,绿的。现在相关的三个类就是这样了:
export class ListArgumentType extends ArgumentType {
static default() {
return [];
}
static convert(value) {
return value.split(',').map(v => this.convertItem(v));
}
static convertItem(value) {
return this.itemClass().convert(value);
}
}
export class StringListArgumentType extends ListArgumentType {
static itemClass() {
return StringArgumentType;
}
}
export class IntegerListArgumentType extends ListArgumentType {
static itemClass() {
return IntegerArgumentType;
}
}
重复代码都没有了吧。接下来是最后一个任务了:“处理整型列表参数数字不合法的问题”。失败的测试:
it('处理整型列表参数数字不合法的问题', () => {
testParsingError('-i 3,123a,7', [
IntegerListSchema('i'),
], 'Invalid integer of flag -i: 123a');
});
保存,红了。可以看到,问题是出错提示里面没有带上参数标志。由于标志信息我们已经传入给 ArgumentType.convert 了,所以这里改起来也很简单,接收这个参数,并传下去就好了。修改 ListArgumentType 类:
static convert(value, flag) {
return value.split(',').map(v => this.convertItem(v, flag));
}
static convertItem(value, flag) {
return this.itemClass().convert(value, flag);
}
保存,绿了。接下来的一个小调整是个人喜好,你可以自己选择是否采纳:
static convert(value, flag) {
return value.split(',').map(this.convertItem(flag));
}
static convertItem(flag) {
return value => this.itemClass().convert(value, flag);
}
保存,还是绿的。恭喜,需求我们都做完了。再看看有没有需要重构的地方。目前 argument-type.js 这个文件貌似有些臃肿了,里面包含 7 个类,而且各个类都还有自己的逻辑。所以,我们把这个文件拆解一下。将 BooleanArgumentType 类,移动到 main/types/boolean-argument-type.js 文件,保存,绿的。同样的手法,将除了 ArgumentType 以外的类,都移动到各自在 main/types/ 下的文件中。最后,直接在 argument-type.js 文件上用 F6,将其移动到 main/types/ 文件夹中。确保测试仍然是绿的。看看我们现在的文件夹结构:
main/types/argument-type.jsboolean-argument-type.jsinteger-argument-type.jsinteger-list-argument-type.jslist-argument-type.jsstring-argument-type.jsstring-list-argument-type.js
argument.jsargument-parser.jsarguments.jserrors.jsschema.jsschemas.jstokenizer.js
test/argument-parser.test.js
以后要是有加入新类型支持的需求,我们只需要在 main/types/ 文件夹中加入一个对应的类定义文件,然后在 main/schema.js 文件中加入一个规则函数(用于更方便的创建规则)就可以了。当然,如果我们完全不要这些规则函数,让用户自己创建 Schema 的对象,我们自己就能更方便——新增类型只需要在 main/types/ 中增加一个文件即可,不涉及其他任何文件的修改。不过,对于我们来说,这些规则函数的维护是非常简单的,以如此小的开销,为我们的用户带来使用上的便利,是很值得的。
好了,以上就是这个习题的所有内容。考虑到篇幅的问题,我们在这里只贴出测试代码,以及 ArgumentParser 这个核心类的代码。整个项目的完整代码,我把它放在了世界的尽头,不,放在了这里:https://github.com/mophy/kata-args-v4。
test/argument-parser.test.js:
import { ArgumentParser } from '../main/argument-parser';
import { BooleanSchema, IntegerListSchema, IntegerSchema, StringListSchema, StringSchema } from '../main/schema';
function testParsingSuccess(commandLine, params) {
let schemas = params.map(param => param.type(param.flag));
let parser = new ArgumentParser(schemas);
let result = parser.parse(commandLine);
params.forEach((param) => {
let { flag, value } = param;
expect(result.get(flag)).toEqual(value);
});
}
function testParsingError(commandLine, schemas, error) {
let parser = new ArgumentParser(schemas);
expect(() => parser.parse(commandLine)).toThrow(error);
}
describe('ArgumentParser', () => {
describe('处理默认参数', () => {
it('处理布尔型参数的默认值', () => {
testParsingSuccess('', [
{ type: BooleanSchema, flag: 'd', value: false },
]);
});
it('处理字符串型参数的默认值', () => {
testParsingSuccess('', [
{ type: StringSchema, flag: 'l', value: '' },
]);
});
it('处理整数型参数的默认值', () => {
testParsingSuccess('', [
{ type: IntegerSchema, flag: 'p', value: 0 },
]);
});
it('处理字符串型列表参数的默认值', () => {
testParsingSuccess('', [
{ type: StringListSchema, flag: 's', value: [] },
]);
});
it('处理整数型列表参数的默认值', () => {
testParsingSuccess('', [
{ type: IntegerListSchema, flag: 'i', value: [] },
]);
});
});
describe('处理 1 个参数', () => {
it('处理布尔型参数', () => {
testParsingSuccess('-d', [
{ type: BooleanSchema, flag: 'd', value: true },
]);
});
it('处理字符串型参数', () => {
testParsingSuccess('-l /usr/logs', [
{ type: StringSchema, flag: 'l', value: '/usr/logs' },
]);
});
it('处理整数型参数', () => {
testParsingSuccess('-p 8080', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
]);
});
});
describe('处理 2 个参数', () => {
it('处理 2 个整数型的参数', () => {
testParsingSuccess('-p 8080 -q 9527', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: IntegerSchema, flag: 'q', value: 9527 },
]);
});
it('处理 2 个布尔型的参数', () => {
testParsingSuccess('-d -e', [
{ type: BooleanSchema, flag: 'd', value: true },
{ type: BooleanSchema, flag: 'e', value: true },
]);
});
it('处理 1 个整型和 1 个布尔型的参数', () => {
testParsingSuccess('-p 8080 -d', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: BooleanSchema, flag: 'd', value: true },
]);
});
it('处理 1 个布尔型和 1 个整型的参数', () => {
testParsingSuccess('-d -p 8080', [
{ type: BooleanSchema, flag: 'd', value: true },
{ type: IntegerSchema, flag: 'p', value: 8080 },
]);
});
});
describe('处理 3 个参数', () => {
it('处理 1 个整型、1 个布尔型和 1 个字符串型参数', () => {
testParsingSuccess('-p 8080 -d -s /usr/logs', [
{ type: IntegerSchema, flag: 'p', value: 8080 },
{ type: BooleanSchema, flag: 'd', value: true },
{ type: StringSchema, flag: 's', value: '/usr/logs' },
]);
});
it('处理 1 个负数、1 个字符串型和 1 个布尔型参数', () => {
testParsingSuccess('-q -9527 -s /usr/logs -d', [
{ type: IntegerSchema, flag: 'q', value: -9527 },
{ type: StringSchema, flag: 's', value: '/usr/logs' },
{ type: BooleanSchema, flag: 'd', value: true },
]);
});
it('处理 1 个布尔型、1 个字符串型和 1 个未传的整型参数', () => {
testParsingSuccess('-d -s /usr/logs', [
{ type: IntegerSchema, flag: 'p', value: 0 },
{ type: BooleanSchema, flag: 'd', value: true },
{ type: StringSchema, flag: 's', value: '/usr/logs' },
]);
});
});
describe('处理异常情况', () => {
it('处理规则未定义的情况', () => {
testParsingError('-b', [
], 'Unknown flag: -b');
});
it('处理整型参数的值不合法的情况', () => {
testParsingError('-p 123a', [
IntegerSchema('p'),
], 'Invalid integer of flag -p: 123a');
});
it('处理传了多余的值的情况', () => {
testParsingError('-d hello', [
BooleanSchema('d'),
], 'Unexpected value: hello');
});
it('处理字符串型参数没有传值的情况', () => {
testParsingError('-s', [
StringSchema('s'),
], 'Value not specified of flag -s');
});
it('处理整型列表参数数字不合法的问题', () => {
testParsingError('-i 3,123a,7', [
IntegerListSchema('i'),
], 'Invalid integer of flag -i: 123a');
});
});
describe('处理列表型参数', () => {
it('处理字符串型列表参数', () => {
testParsingSuccess('-s how,are,u', [
{ type: StringListSchema, flag: 's', value: ['how', 'are', 'u'] },
]);
});
it('处理整型列表参数', () => {
testParsingSuccess('-i 1,-3,2', [
{ type: IntegerListSchema, flag: 'i', value: [1, -3, 2] },
]);
});
});
});
main/argument-parser.js:
import { Arguments } from './arguments';
import { Argument } from './argument';
import { Tokenizer } from './tokenizer';
import { Schemas } from './schemas';
export class ArgumentParser {
constructor(schemas) {
this.schemas = new Schemas(schemas);
}
parse(commandLine) {
this.createDefaultArguments();
this.tokenizeCommandLine(commandLine);
this.parseTokens();
return this.args;
}
createDefaultArguments() {
this.args = new Arguments(this.schemas.map(this.createArgument));
}
createArgument(schema) {
return new Argument(schema.flag, schema.type.default());
}
tokenizeCommandLine(commandLine) {
this.tokens = new Tokenizer(commandLine);
}
parseTokens() {
while (this.tokens.hasMore()) this.parseToken();
}
parseToken() {
let flag = this.tokens.nextFlag();
let schema = this.schemas.find(flag);
let value = this.nextValue(schema.type, flag);
this.args.set(flag, value);
}
nextValue(type, flag) {
let value = type.needValue() ? this.tokens.nextValue(flag) : undefined;
return type.convert(value, flag);
}
}
我们对实现代码做一个简单的统计:
- 文件数:14 个
- 文件行数
- 最小:7 行
- 最大:47 行
- 平均:18.2 行
- 方法大小
- 最小:1 行
- 最大:4 行
- 平均:1.3 行
总结
如果你是一路跟着文章练到现在,相信已经通过亲身体会的方式,掌握了 TDD 的相关方法。我们来简单复习一下。
开发流程:
- 沟通确认需求(确定输入和输出)
- 拆分任务(越小、实现越简单越好)
- 编写代码(红、绿、重构)
编码流程:
- 失败的测试(红)
- 快速通过(绿)
- 重构
现在我们再摆出 TDD 的好处,看看你有没有在本次阅读和操作过程中亲身体会到:
- 让你倍有面子——别人不会,你会(开个玩笑)
- 产品质量更高——没机会写 bug,领导喜欢,绩效好
- 开发速度更快——不写 bug,不改 bug,早早回家睡觉
- 开发难度更低——能解决别人解决不了的问题,或者,参考前两条
- 返工成为历史——不再被产品经理怒怼
- 维护风险更低——改需求不再“按下葫芦浮起瓢”
浏览代码,可以看到,最终的代码是非常清楚和简洁的。你也明白了,这样的代码不是一蹴而就的,而是通过无数个微小的步骤,逐渐打磨出来的。如果只计方法体中的代码,本文中的每次代码修改,基本都在 2 行以内。这样的小步子,是你能获得 TDD 相关好处的关键因素。同时也是衡量一个人 TDD 做得好不好的关键指标。
实际工作中,你是可以按需调整步幅的。当你感觉放心的时候,可以步子大一点;当你觉得没把握的时候,可以步子小一点。但是,当你的极限是一次 10 步的时候,即使是处理棘手的情况,你也没法做到每次 2 步。这就是我们反复练习,提高自己极限的原因。当你能够达到每次 1 步,那么你会有足够的信心和能力,处理任何复杂问题。而这个能力,看文章、看书、听讲座,都得不到,只有靠多练。好消息是,习题多的是:http://codingdojo.org/kata/。
此外,以下几点也希望你能记得:
- 测试代码和生产代码同等重要
- 测试代码也可以写得很漂亮、很容易维护
- 用户视角,让用户用起来简单、不容易出错
好,终极问题来了,“你说这些东西,我们工作里面用不上啊,我们前端/后端情况比这个复杂,需要考虑的东西很多”。是的,这也是 TDD 没有被推行起来的重要原因之一。不过不用担心,无论是前端还是后端,都可以做 TDD 的,只是需要一些技巧。具体做法,请期待接下来的文章,再会:)
参考链接
[1]: https://www.jianshu.com/p/62f16cd4fef3 深度解读 – TDD(测试驱动开发)
[2]: https://jestjs.io/docs/en/expect.html Jest Expect
[3]: https://github.com/unclebob/javaargs/tree/master The Java version of the Args Program
[4]: https://www.jianshu.com/p/38493eb4ffbd 工厂设计模式(三种)详解
[5]: https://en.wikipedia.org/wiki/Code_refactoring Code refactoring
[6]: https://baike.baidu.com/item/%E7%AD%89%E4%BB%B7%E7%B1%BB%E5%88%92%E5%88%86/4219313 等价类划分

{kind=link}
{kind=link}